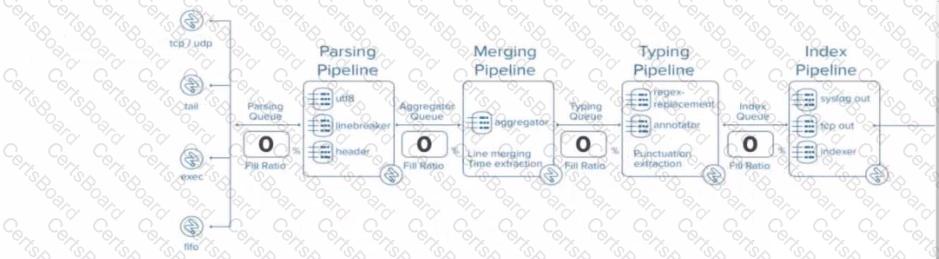
In Splunk, SEDCMD (Stream Editing Commands) is applied during the Typing Pipeline of the data indexing process. The Typing Pipeline is responsible for various tasks, such as applying regular expressions for field extractions, replacements, and data transformation operations that occur after the initial parsing and aggregation steps.
Here’s how the indexing process works in more detail:
Parsing Pipeline: In this stage, Splunk breaks incoming data into events, identifies timestamps, and assigns metadata.
Merging Pipeline: This stage is responsible for merging events and handling time-based operations.
Typing Pipeline: The Typing Pipeline is where SEDCMD operations occur. It applies regular expressions and replacements, which is essential for modifying raw data before indexing. This pipeline is also responsible for field extraction and other similar operations.
Index Pipeline: Finally, the processed data is indexed and stored, where it becomes available for searching.
Splunk Cloud Reference: To verify this information, you can refer to the official Splunk documentation on the data pipeline and indexing process, specifically focusing on the stages of the indexing pipeline and the roles they play. Splunk Docs often discuss the exact sequence of operations within the pipeline, highlighting when and where commands like SEDCMD are applied during data processing.
Source:
Splunk Docs: Managing Indexers and Clusters of Indexers
Splunk Answers: Community discussions and expert responses frequently clarify where specific operations occur within the pipeline.